
Water-to-air backscatter communications (WABCom)
This work was supported in part by the European Union’s Horizon 2020 research and innovation programme under grant agreement No. 898893.
Background and objectives
Over 70% of the Earth’s surface is covered by water, while the majority of the underwater areas are unexplored yet. Owing to growing underwater activities, e.g., undersea oil & gas exploration, and the Internet of underwater things (IoUT), which are expected to connect various underwater sensors and autonomous underwater vehicles (AUVs) to the outside world, reliable water-to-air wireless communications are urgently needed by the industry, military, and scientific communities. However, it is difficult to communicate across a water-air interface using a single type of wireless signal, e.g., acoustic, radio frequency (RF), or optical. RF signals decay exponentially in water. Although acoustic and optical signals can travel over long distances underwater, they both suffer from severe reflections off the water surface and hence cannot transmit smoothly across the water-air interface. To overcome the water-air barrier, most existing water-to-air communications rely on sonobuoys, which are floating devices that receive acoustic signals from underwater transmitters and then RF transmits them to receivers on/above the water surface. Presently, battery-powered sonobuoys use magnesium/silver chloride or lithium primary batteries, which are full of toxic metals and tend to vent toxic fumes during discharging. As they might not be retrieved from remote, hostile areas of the ocean, battery-powered sonobuoys are posing a great threat to the marine environment. Although energy-harvesting technologies (e.g., solar, wave, or seawater semi-fuel cell) have been developed for sonobuoys to charge onboard energy storage systems, the challenge of miniaturizing and incorporating these technologies into the sonobuoy volume constraint remains a dominant issue. Large sonobuoys would require complex mooring systems, thus limiting their wide deployment for water-to-air communications. Miniature/lightweight battery-free sonobuoys, which can be flexibly deployed (e.g., air-dropped by unmanned aerial vehicles (UAVs)) where and when needed and are disposable with a minimum impact on the marine environment, are in high demand for many ocean applications, such as underwater search and rescue (SAR), IoUT, oil spill monitoring, and scientific exploration. Since RF communication is the major source of energy consumption for sonobuoys, a battery-free design of sonobuoy can leverage backscatter communications, which allow a device to communicate at near-zero power by reflecting an existing RF signal, thus leading to novel water-to-air backscatter communications (WABCom). The project validates the feasibility of the proposed WABCom system through a comprehensive approach that includes mathematical simulations, prototyping, and extensive experimentation. The results demonstrate the potential of the proposed system, and the innovation activities of the project can lead to the development of new products, services, reference materials, processes, or methods that can be launched into the market. These developments have significant benefits for various industries and government agencies involved in underwater IoT, underwater detection, marine biology research, oil exploration, and emergency rescue.
Main works and contributions
The main works and results of the project are listed below. 1) Efficient energy harvesting for a battery-free buoy: The project has successfully developed and implemented efficient energy harvesting techniques that can harvest enough power from an in-air RF transceiver to operate a buoy without the need for a battery. The development of these techniques involved the integration of rectifier design, RF impedance matching, high-frequency circuit design, simulation, and fabrication. 2) Water-to-Air Backscatter Communication: The project has also achieved a breakthrough in the development of water-to-air backscatter communication technology, which allows for low-cost and low-power communication in marine environments. This involves transmitting data from an underwater acoustic transmitter to the buoy, and from the buoy to an aerial receiver. 3) Optimization of the buoy’s circuit: The project has successfully optimized the buoy’s circuit to increase the amount of energy harvested from the RF signals while ensuring high signal-to-noise ratio (SNR) water-to-air backscatter communications. This required careful selection of components and tuning of the circuit to match the impedance of the energy source and make a trade-off between the SNR of the water-to-air backscatter communications and the energy harvesting efficiency. 4) Enhanced robustness: The project has designed and tested the battery-free buoy to withstand dynamic marine environments. The project studied the relationship between the buoy’s motion and water surface movement and developed a pilot-based channel estimation and equalization method to reduce the impact of the dynamic water surface on the backscatter communication channel. 5) Real-World testing: The project has built a prototyping for the battery-free buoy and implemented a test bed to evaluate and validate the buoy’s performance on a wavy water surface. This involved testing the buoy in a controllable wave tank and measuring its performance under different wave patterns to identify any design flaws in the buoy’s shape, the proposed backscatter communication technology, and the channel estimation and equalization methods. These results will help refine the technology for future practical applications.
Battery-free wireless sensor nodes for backscatter communications
The proposed node harvests energy from RF signals at RFID frequency bands, and then reflects the RF signals embedded with the raw signals from analog sensors, e.g., nanogenerators, microphones and piezo sensors. The node enables microwatt-level uplink and downlink communications to an RFID Reader at a distance of a couple of meters.
As an example of application scenarios, the battery-free nodes are deployed in hazardous environments, .e.g, caves, forests and oceans. A low-altitude drone equipped with an RFID Reader collects the data from the nodes by flying along the nodes one by one. The battery-free design in wireless sensor networks improves the scalability and lifetime of wireless sensor nodes by removing the cost of battery maintenance.
The figures below show the PCB and node design, S11 and the received spectrums of the 2-FSK signals in backscatter communications. The reflection coefficient from the proposed circuit (S11) in the first figure is measured by a Rohde & Schwarz network analyzer, which indicates the circuit has good impedance matching at the target frequency (915 MHz). In this project, Keysight ADS is used for impedance matching, schematic and PCB design, and the Large-Signal S-Parameters (LSSP) and harmonic balance simulation. Ettus USRP is used to evaluate the system’s performance. An ultra-low power chip (TI MSP430) supports power management in energy harvesting and wireless modulation and demodulation in backscatter communications.
 |  |
|---|---|
A brief demonstration of the energy harvesting is shown in the video below.
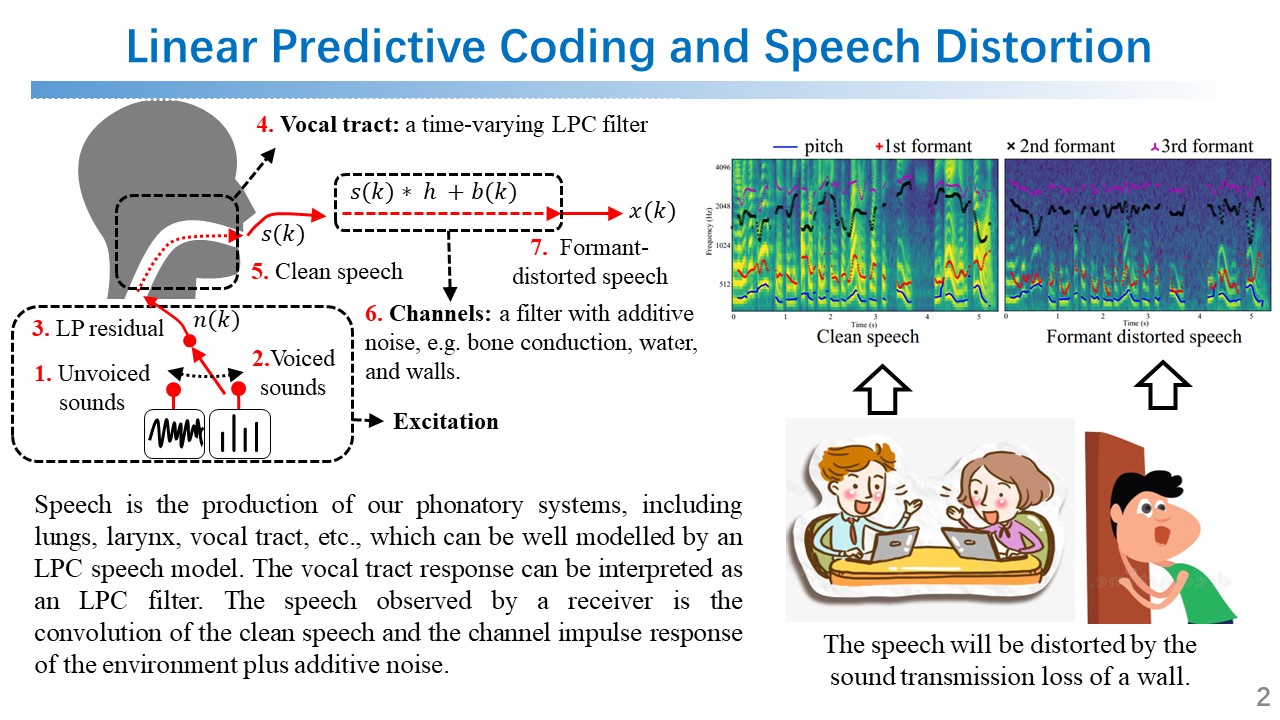
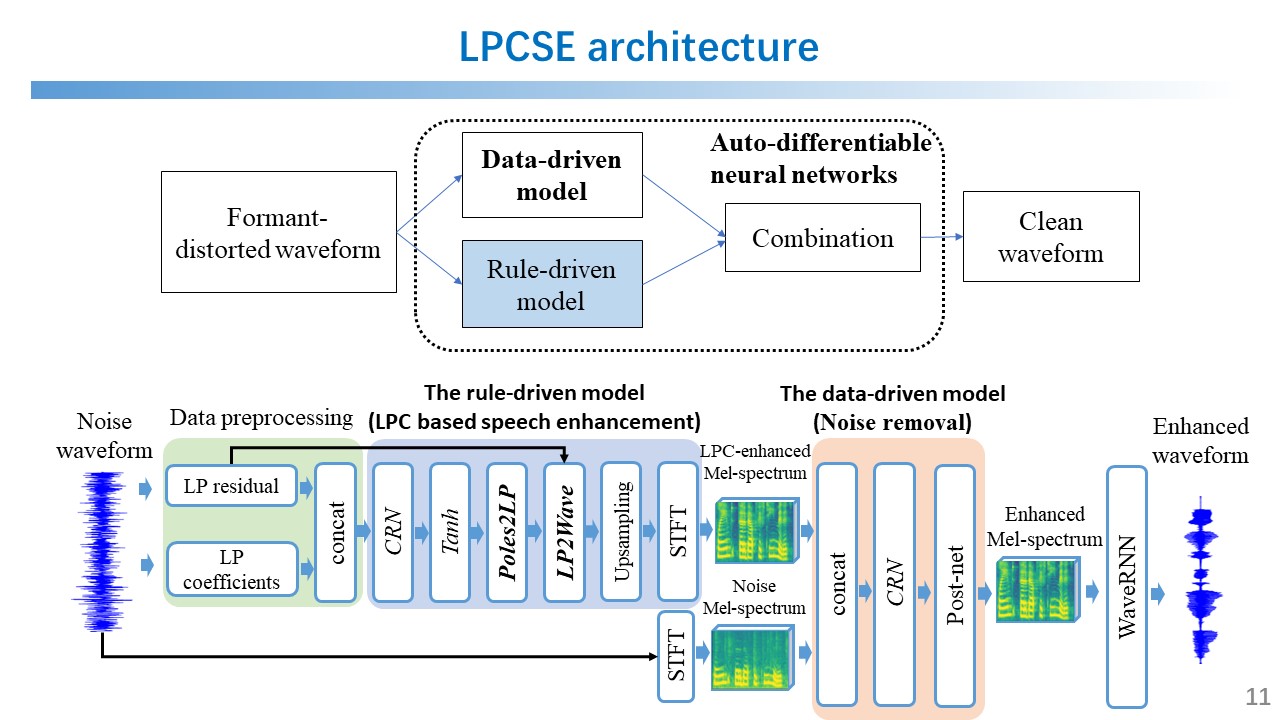
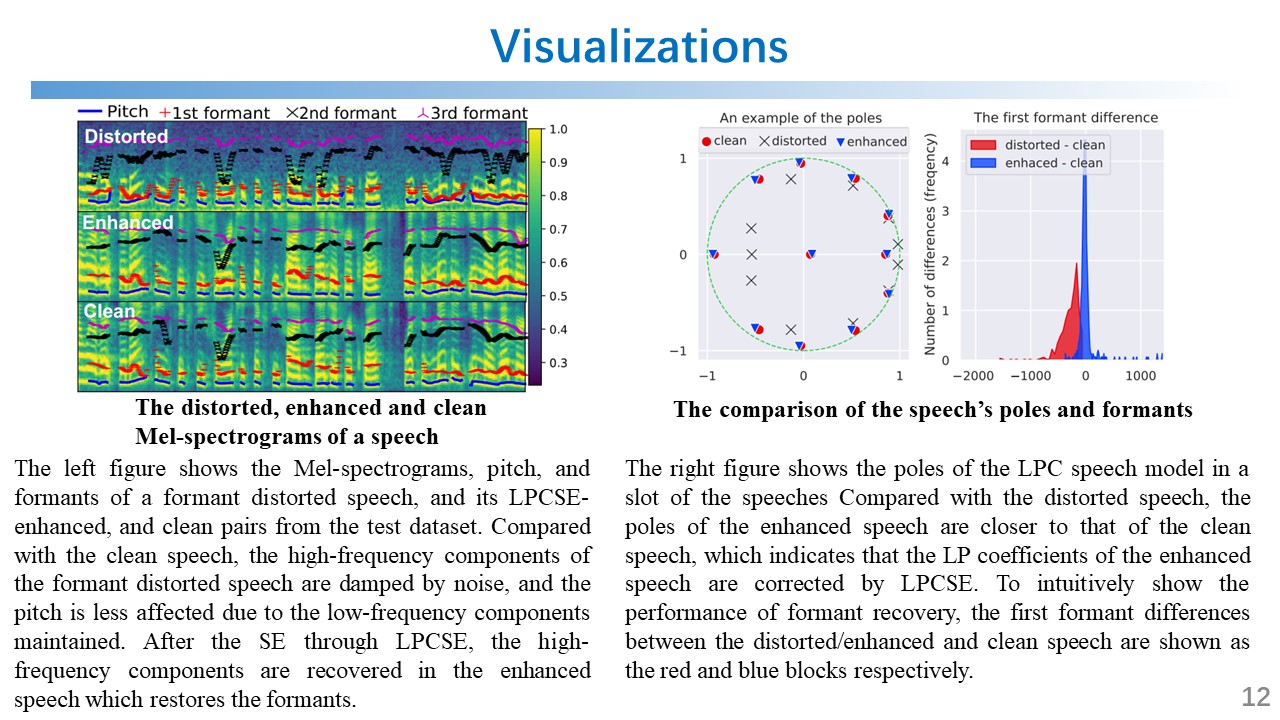
LPCSE: Neural Speech Enhancement through Linear Predictive Coding (IEEE GLOBECOM’22)
I proposed a new speech enhancement architecture called LPCSE that aims to address the challenge of acoustic frequency selective fading in objectives, such as water, wall, and face masks. The proposed architecture combines classic signal processing technologies, i.e., Linear Predictive Coding (LPC), with neural networks in the auto-differentiable machine learning frameworks, as shown in the figures below. The proposed architecture could leverage the strong inductive biases in the classic speech models in conjunction with the expressive power of neural networks. To achieve this work, I also studied the speech synthesis and enhancement technologies, such as speech vocoders (WaveNet WaveRNN, MelGAN HiFi-GAN, etc.), denoising (SEGAN, U-net, etc.), voice conversion (AutoVC, StarGAN-VC, etc.), and expert-rule inspired speech and audio synthesis (LPCNet, DDSP, etc.).
 |  |  |
|---|---|---|
A brief introduction to this project is shown in the video below.