
LPCSE: Neural Speech Enhancement through Linear Predictive Coding [paper]
I proposed a new speech enhancement (SE) architecture called LPCSE that combines classic signal processing technologies, i.e., Linear Predictive Coding (LPC), with neural networks in the auto-differentiable machine learning frameworks, as shown in the figures below. The proposed architecture could leverage the strong inductive biases in the classic speech models in conjunction with the expressive power of neural networks. To achieve this work, I also studied the speech synthesis and enhancement technologies, such as speech vocoders (WaveNet WaveRNN, MelGAN HiFi-GAN, etc.), denoising (SEGAN, U-net, etc.), voice conversion (AutoVC, StarGAN-VC, etc.), and expert-rule inspired speech and audio synthesis (LPCNet, DDSP, etc.).
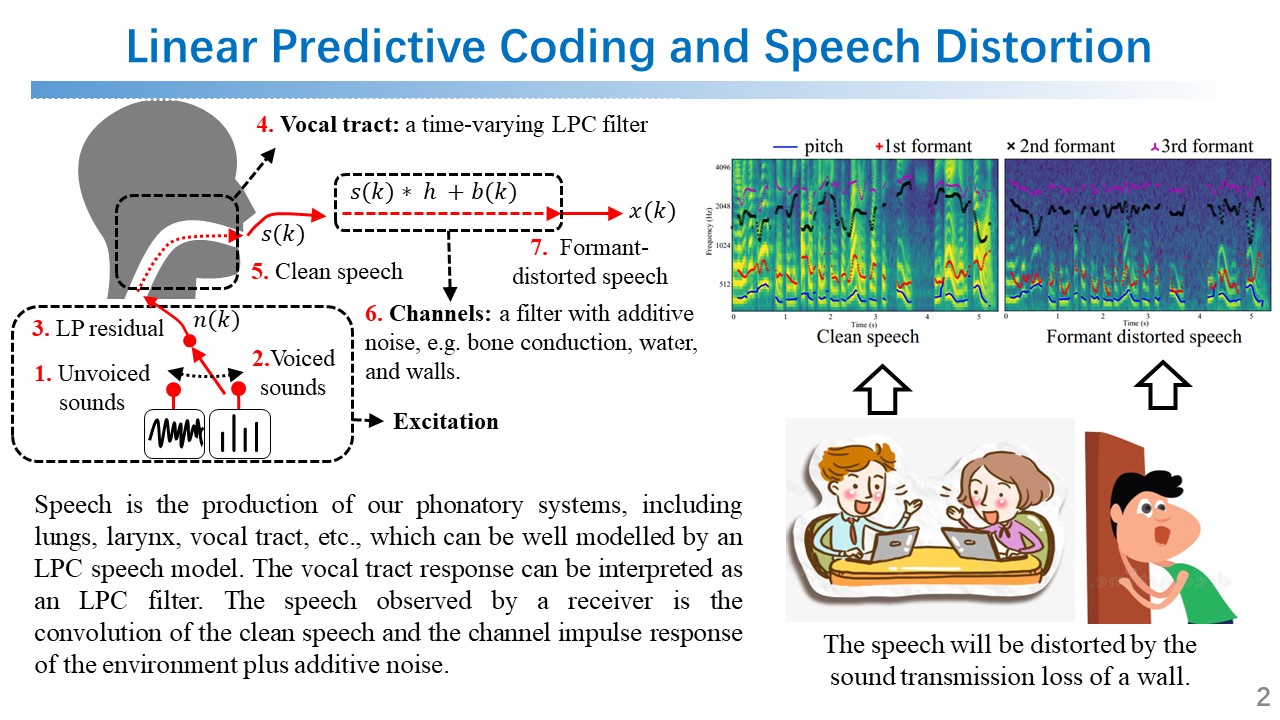 LPC Model and Application Scenario Illustration of the LPC model and its deployment in real-world audio enhancement. | 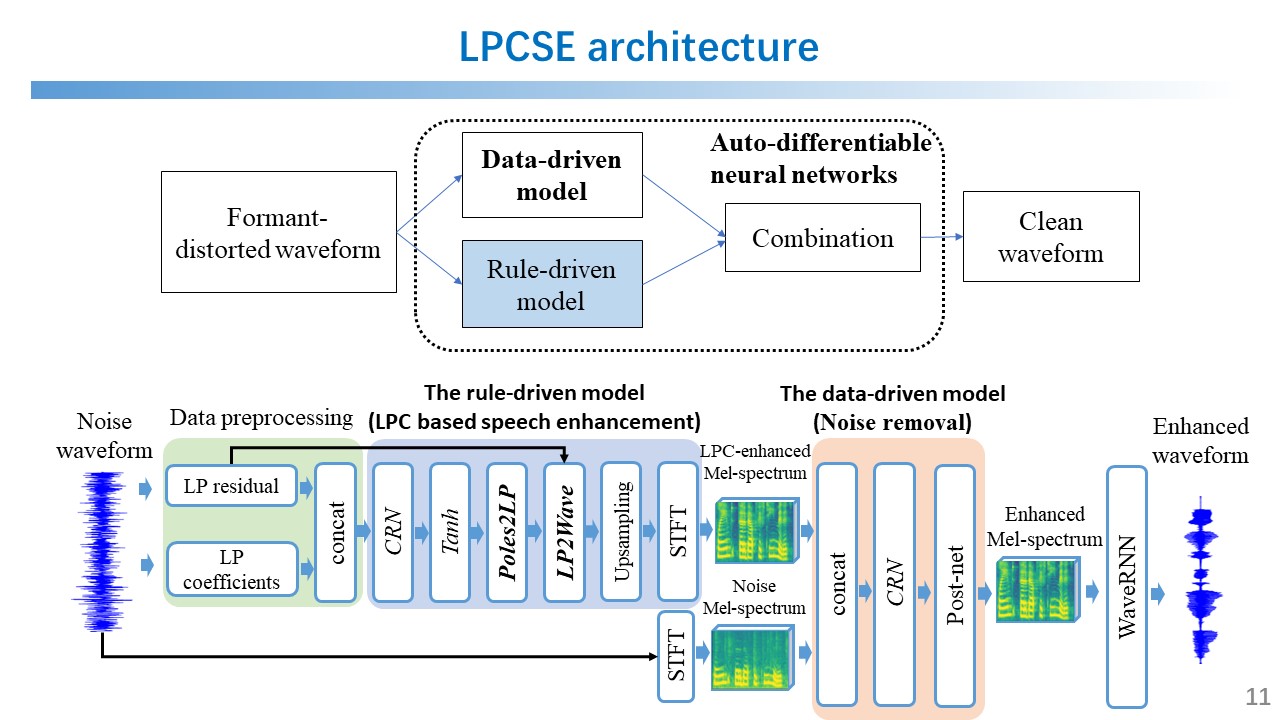 LPCSE Architecture System design showing the integration of rule-driven and data-driven models for SE. |
 LPCSE Architecture (Detailed Module Design) Architecture of the rule-driven and data-driven components for LPC-based SE. | 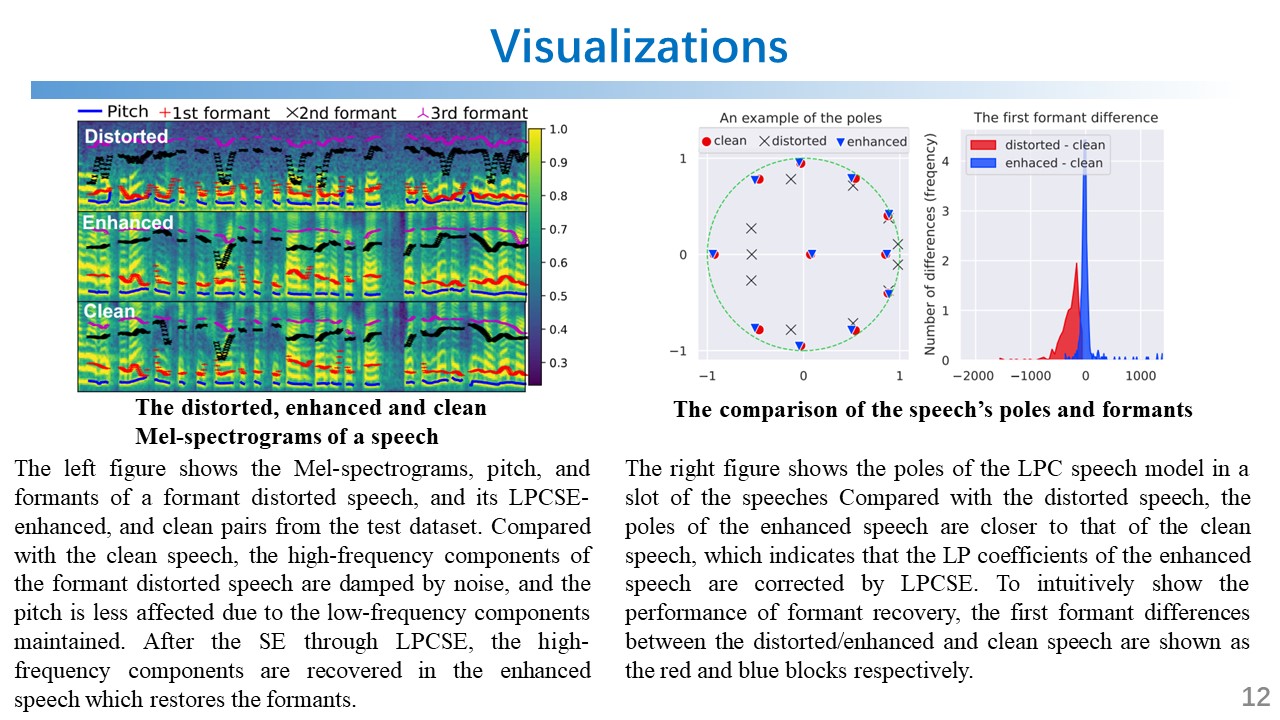 Visualization of LPCSE Results Comparison between noisy, distorted, and LPCSE-enhanced Mel-spectrograms. |
A brief introduction to this project is shown in the video below.